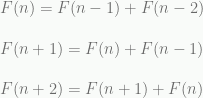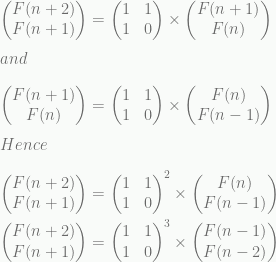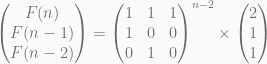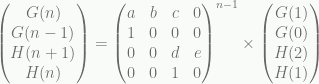What is a Tree :
Tree is a heirarchial arrangement of nodes. From the literal meaning of Tree we know that it has root, branches, fruits and leaves. Well, in Algorithms also, we have a root – which is the origin of the tree. We have branches which connect to smaller trees and we have leaves, which do not have outgoing branches. And as far as the fruits are concern – depending on the complexity of operations that can be perform, we may label the fruits as sweet and sour !
The simplest tree would be a node which branches to exactly one other node, or in other words – a singly Link List. If every node branches to its child and also to its parent, we have a doubly link list. But in this post, we are not going to discuss these.
The next level of trees would be – where a single node may branch out to a maximum of two other nodes. Such a tree is call a binary tree. Binary trees are some of the most widely us datastructures in computers and we are going to discuss them in a series of posts. So lets begin.
One of the most important things to do is : Create a tree.
So what is it that we ne to create one. We will ne to represent the nodes and the links between nodes. And since we ne to connect to a maximum of two nodes, we will have two branches. We shall call these branches – left and right. Also, it will store some data in it. Our tree will be us to just store integers.
We will use the following structure to create it. FYI, everything here is in C++ and not C.
struct NODE {
int data;
NODE *left;
NODE *right;
};
Now whenever we ne to insert a node, we ne to make sure that there is a fix position at which the node will be insert given its value (Data in the node). Let us follow a simple strategy.
We will insert a node to the left of a ‘Parent node’, if its value is lesser than the value of the Parent, otherwise to the right. The binary trees which use such a strategy are call Binary Search Trees.
The obvious advantage of such a strategy is that we can search for elements in the tree in O(h) time, where h is the height of the tree. Do note that, in general, h does not equal logN. If we could actually have a tree where the height is inde logN, we would call such trees as Balanc Binary Search Trees.
Alright then, lets get our hands dirty with a code that will create the tree for us. The function insert takes as input the root of the tree and the value to be insert and returns the node which contains the data.
NODE * insert(NODE *root, int data) {
if(root==NULL) {
root=(NODE*)malloc(sizeof(NODE));
root->left=root->right=NULL;
root->data=data;
return root;
}
else {
while(root!=NULL) {
if(root->data>data) {
if(root->left!=NULL) root=root->left;
else break;
}
else {
if(root->right!=NULL) root=root->right;
else break;
}
}
NODE *new_node=new NODE;
new_node->data=data;
new_node->left=new_node->right=NULL;
if(root->data > data) {
root->left=new_node;
}
else root->right=new_node;
return new_node;
}
}
Another very useful and important property when using the above strategy is, that the INORDER traversal is sort!
Lets backup a bit. What are Traversals. It is like visiting many homes using the roads which connect them. Only that, the homes here are the NODEs and the roads are the links between each node.
There are many traversals but the three us very often are – PreOrder, InOrder and PostOrder.
In PreOrder, you print the current node and then visit its left and then its right children, recursively.
In InOrder, you first visit the left child, once you have return, you print the current value and then visit the right child.
In PostOrder, you visit both your children and then print the current value.
Here is the code snippet for the InOrder traversal (recursive version).
void inorder(NODE *root) {
if(root!=NULL) {
inorder(root->left);
printf("%d ",root->data);
inorder(root->right);
}
}
You could write an iterative version, where you would simulate the operations in a system stack, using your own stack. The obvious advantage is that you would be saving space (since you would now push as many values as the system would for a function call.)
However, there exists a really beautiful iterative version which does not use a stack. It assumes that two pointers can be check for equality. It is bas on thread trees and it was first written in 1979 by Morris and hence the name!
How does it work.
The only reason we ne a stack is so that we can do the “RETURN” from child nodes to parent nodes. This return is ne only from one node really. Consider a 5 node tree.
20
/ \
/ \
10 30
/ \
/ \
5 15
Now our stack would work like this.
1. Push 20.
2. Push 10.
3. Push 5.
4. Pop 5 and print 5.
5. Pop 10 and print 10.
6. Push 15.
7. Pop 15 and print 15.
8. Pop 20 and print 20.
9. Push 30.
10. Pop 30 and print 30.
If I write a non-resursive and non-stack version, my greatest headache would be to go to 20 from 15 (statements 7-8). So we need to link 15 and 20 so that we can go to 20 without problems. But that would mean that we are modifying the tree. Well, we could do it in two steps. First we link the two and in the next step once we have printed 20, we can destroy that link.
20
/ | \
/ | \
9 | 30
/ \ |
/ \|
5 15
And thus we have the following –
1. SET current as root.
2. if current is not null do –
2.a. if current has no left child, print current , set current as right child and REPEAT 2.
2.b. else goto the rightmost child of current’s left child.
2.b.a. If this is NULL, then link it to current and set current as left child of current and REPEAT 2.
2.b.b. else set the right child to NULL. Print Current. Set current as Current’s right child . REPEAT 2.
As a pseudocode we may write it as –
Morris-InOrder ( root )
current = root
while current != NULL do
if LEFT(current) == NULL then
print current
current=RIGHT(current)
else do
// set pre to left child of current
pre=LEFT(current)
// find rightmost child of the left child of current
while (RIGHT(pre) != NULL and RIGHT(pre) != current) do
pre=RIGHT(pre)
//if thus is null, link it to current and set current's left as current
if RIGHT(pre) == NULL then
RIGHT(pre)=current
current=LEFT(current)
// else unlink it, print current and set right child of current as current
else do
RIGHT(pre)=NULL
print current
current=RIGHT(current)
Looks nice aah. Let’s just write the code.
void MorrisInorder(NODE *root) {
NODE* current,*pre;
current=root;
while(current!=NULL) {
if(current->left==NULL) {
printf("%d ",current->data);
current=current->right;
}
else {
pre=current->left;
while(pre->right != NULL && pre->right !=current)
pre=pre->right;
if(pre->right==NULL) {
pre->right=current;
current=current->left;
}
else {
pre->right=NULL;
printf("%d ",current->data);
current=current->right;
}
}
}
}
Now, lets talk about the fruits!
Insert happens in O(h) time. Each of the traversals (recursive and iterative versions using stack) are in O(N) time and O(N) space (system stack or normal stack).
Morris Inorder runs in O(NlogN) time and O(1) space. One could say that it is slower which is true, but the fact that it does not use additional space can be a huge boost in situations where you are low on system memory!
The entire code is available on :PASTEBIN
I hope you gathered all that info well! I will post a Tree 102, in which I shall discuss the delete operation and talk more about balanced trees!